
絶版マンガ図書館
http://zeppan.com/
というのがあって、絶版になった本を集めて公開しています。いろいろ経緯は絶版マンガ図書館を読んで貰うとして、この本には広告が挟み込んであってそれが収入代わりになっています。絶版本なので、古い漫画が多いのですが、漫画歴の長い私としては懐かしい本やらファンな本があって、何かと手伝いたい感じだったので、勢いで作ってみました。いや、単に Kindle Launcher と同じ形式にしたできた、ってだけなんですけどね。
絶版マンガ図書館 Launcher
http://apps.microsoft.com/windows/ja-jp/app/launcher/69c16e83-005c-49a3-ac83-6414b08d89fd
Windows 8.1 以降でどれくらいの人が読むのか?は謎なのですが、まあ良しとしましょう。
確か、Jコミの頃から API とかは無かったんですよね。なので、清く HTML ページからサルベージして情報を抜き出すようにしています。レイアウトが変わったり、id や class が変わると呼び出せなくなってしまうのですが、まあ、そのときはそのときに追随するとして。
■ストアアプリで WebView を使う
データを取得するときには、HttpClient を使うか、WebView を使って間接的に使うかします。今回の場合、書式が HTML 形式なので、WebView を使うことにしました。WinRT の場合、手軽な HTML パーサがないのが難点ですよね。処理が XML にまとまっているのはいいのですが、こんな風な時はちょっと手間です。
ただし、試してみると、WebView はコード上で new をしても使えることがわかりました。つまりは画面に出さなくても使えるんですよね。まあ、非表示にして使ってもいいのですが、今回のコードでは中で new しています。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | private void OnButtonItemSearch(object sender, RoutedEventArgs e){ string text = vm.Title; if (text == "") return; string url = string.Format("http://www.zeppan.com/title/?query={0}&submit=", System.Net.WebUtility.UrlEncode(text)); var web = new WebView(); web.NavigationCompleted += async (_,__ ) => { string[] para = { "$('#title').html();" }; string html = await web.InvokeScriptAsync("eval", para); Debug.WriteLine(html); html = html.Replace(".jpg">", ".jpg"/>").Replace("<br>", "<br/>"); html = "<root>" + html + "</root>"; var books = GetBooks(html); this.vm.Books = books; }; web.Navigate(new Uri(url));} |
問題は、WevView の中身を取り出す方法です。実は、Microsoft のサンプルにこの方法が乗っています。Javascript をインジェクションして eval 実行させるという技ですね。なるほど。サンプルには document.title のような簡単な例があったのですが、コード見て分かるように jQuery が動きます。と言いますか、サイトが jQuery を使っていると、こんな風に手軽に HTML コードが取り出せるよ、という例です。
ただ、ここで難点なのは、HTML 文字列を取り出した後にパースする手段がないということです。
Deathspike/HtmlAgilityPack-PCL
https://github.com/Deathspike/HtmlAgilityPack-PCL
を使うとパースできるのかもしれません。試していませんが。
仕方がないので、コードを replace して XML パースができる状態にしてしまいます。取り出すときのコードを見る限り img と br が不正になってしまうので、ピンポイントでそこだけ変えています。まあ、jQuery が使えるので、インジェクションする javascript のほうで、適当に XML 形式に直す関数を作って eval するのがよいでしょうね。
■パース済みの XML から ExDoc を使う
数年前からちまちまと作っている/使っているライブラリですが ExDoc で値を取り出します。ExDoc はこういう適当な XML データから適当に値を取り出すのに便利なライブラリです。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | BookList GetBooks(string html){ var doc = ExDocument.LoadXml(html); var books = new BookList(); ExElements items = doc * "div" % "class" == "sakuhin open-detail"; foreach (var it in items) { var book = new Book(); book.Title = ((ExElement)(it * "div" % "class" == "rdtx")).Value.Trim(); book.Author = ((ExElement)(it * "div" % "class" == "color888")).Value.Trim(); book.ASIN = it * "div" % "data-baid"; book.IconUrl = it * "img" % "src"; book.IconUrl.Replace("thumbnail", "cover"); books.Add(book); } return books;} |
■見た目は Kindle Launcher と一緒
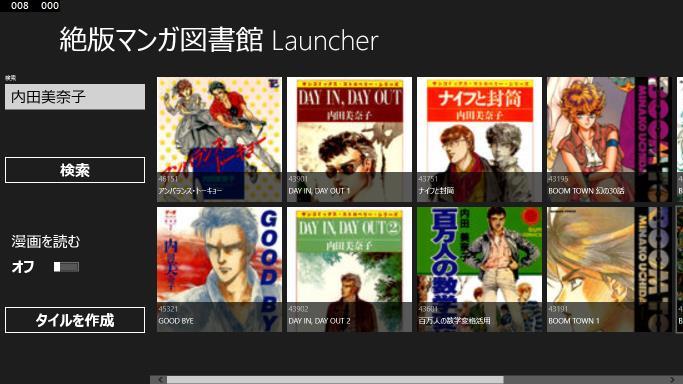
UI を考えるのが面倒だったというのもありますが、データバインドさせて GridView で表示しているところは一緒です。Kindle API を使っても、絶版マンガ図書館の HTML を直接弄っても同じように使える、ということです。後は青空文庫まわりで「えあ草子」か「青空文庫リーダー・ライト」を個別呼び出しとか。

