
端的に言えば「User-Agent」を偽装します、ということです。
User-Agent というのは、HTTP プロトコルのヘッダ部に設定してある「今、私はこのブラウザを使っています」という印ですね。サーバーのほうで、携帯電話からなのか、PC からなのか、iPhone/iPad からなのか、Android からなのか、ということが分かります。
と、云いますか、当然これは「印(ルール)」でしかなくって、WebClinet クラスなり、Firefox のプラグインを利用するすれば、簡単に自分が何者かを偽装するこができます(「詐称」という言葉を使っているところもあるけど、技術的にすり替えるだけなので「偽装」のほうがよいかなと)。
さて、なぜ iphone 専用のサイトを pc から覗く必要があるかというと、hon.jp の api を利用して amazon 風のブログパーツを作りたいからなのです。amazon ブログパーツは、書籍の画像を返してくれるのですが、hon.jp api は、画像を返してくれません。hon.jp の場合、タイトル検索などのテキスト検索が主なので、電子書籍の画像は各社のサイトの中にしかありません。pc 用の電子書籍がある場合は、pc からキャッシュ的に取得すればよいのですが、iphone 用しかない場合には、iphone 用のページにアクセスする必要があります。なので、画像を取得するためには iphone であると偽装して画像用の url を取得しないと駄目なのです。
と前置きはそれくらいにして、ざっとこんな感じ。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | private void button2_Click(object sender, EventArgs e){ // url を取得 string url = textBox1.Text; WebClientEx client = new WebClientEx(); // cookie を設定 client.Cookie = new CookieContainer(); client.Headers.Add("User-Agent", "Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_4 like Mac OS X; ja-jp) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8K2 Safari/6533.18.5"); // sjis で全て読み込み StreamReader sr = new StreamReader(client.OpenRead(url), Encoding.GetEncoding("shift_jis")); string content = sr.ReadToEnd(); sr.Close(); // ファイルに出力 StreamWriter sw = new StreamWriter("temp.html", false, Encoding.GetEncoding("shift_jis")); sw.Write(content); sw.Close(); // ブラウザコントロールで表示 webBrowser1.Navigate("file://" + @"D:\work\blog\src\SampleUserAgent\SampleUserAgent\bin\Debug\"+ "temp.html"); // テキストボックスでも表示 textBox2.Text = content;} |
文字コードが sjis になっているのは、電子文庫パブが sjis で返すからです。本来は charset を見てコードを判別しないと駄目ですね。また、電子文庫パブの場合は、cookie が必要になるのでこれも設定してます。
Cookie 自体は、内部の HttpWebRequest を弄る必要があるので、こんな風に継承したクラスを作ります(という例があった)。
1 2 3 4 5 6 7 8 9 10 | class WebClientEx : WebClient{ public CookieContainer Cookie { get; set; } protected override WebRequest GetWebRequest(Uri address) { HttpWebRequest wreq = base.GetWebRequest(address) as HttpWebRequest; wreq.CookieContainer = this.Cookie; return wreq; }} |
実行するとこんな感じで取得できます。
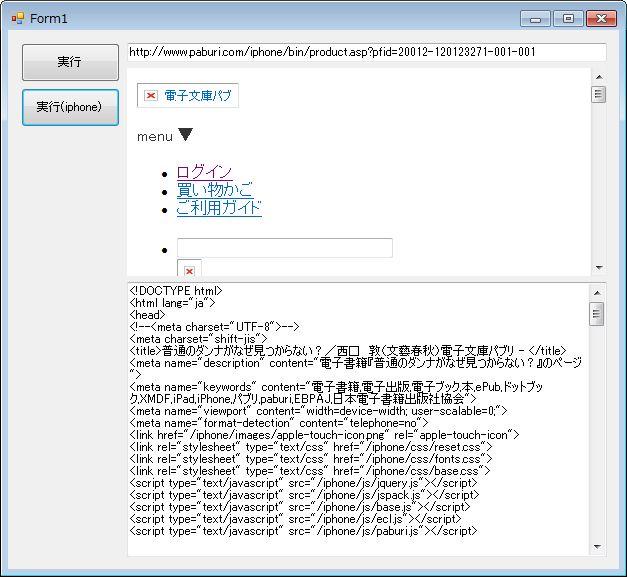
画像が表示されないのは、img タグの src 相対パスになっているからです。
保存した html ファイルを開いて
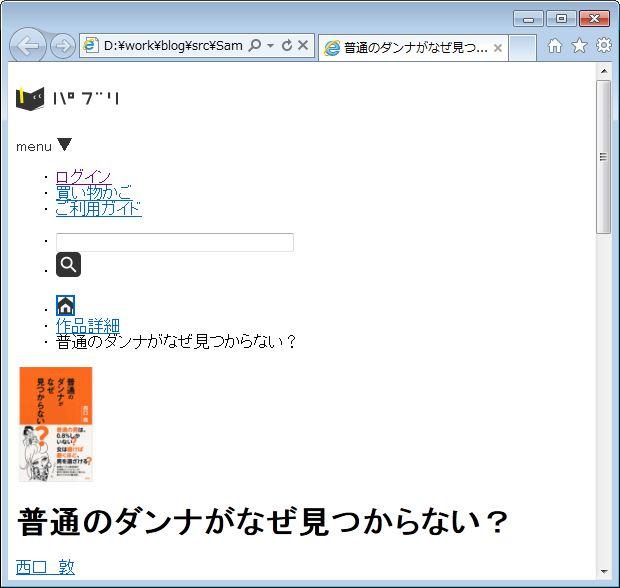
これで画像の url が分かるので、ブログパーツを表示する時に画像が表示できますね。
画像 url が変わる可能性もあるのでキャッシュしてもいいのですが、まぁ、amazon と同じで画像ファイル名はほとんど変わらないのではないかなと。これは、いくつかの電子書籍の会社を探ってから考えましょう。
■参考
userAgent一覧/ユーザーエージェント一覧
http://www.openspc2.org/userAgent/

