
OpenCV で機械学習を試してみる…とまだ終わらず | Moonmile Solutions Blog
http://www.moonmile.net/blog/archives/2537
を、「-m 500」に設定して4時間程動かすと XML ファイルが出来上がりました。
検出用のプログラムをざっと作って、
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | #include "stdafx.h"#include <iostream>#include "opencv/cv.h"#include "opencv/highgui.h"using namespace std;int main(int argc, char* argv[]){ /* 画像のロード */ char *fname = argv[1]; cv::Mat image = cv::imread( fname ); /* 検出器のロード */ // char *cascadeName = "C:\\OpenCV2.3\\data\\haarcascades\\haarcascade_frontalface_default.xml"; char *cascadeName = "D:\\work\\OpenCV\\src\\PiyoDetect\\PiyoML\\data\\koma01.xml"; cv::CascadeClassifier cascade; cascade.load(cascadeName); /* 検出 */ vector<cv::Rect> komas; cascade.detectMultiScale( image, komas ); /* 検出領域の描画 */ for ( vector<cv::Rect>::iterator it=komas.begin(); it!=komas.end(); ++it ) { cv::rectangle( image, cv::Rect( it->x, it->y, it->width, it->height ), cv::Scalar(0,255,0)); } cout << "count: " << komas.size() << endl; /* 画像の表示 */ cv::namedWindow("result", CV_WINDOW_AUTOSIZE|CV_WINDOW_FREERATIO); cv::imshow("result", image ); cv::waitKey(0); return 0;} |
を動かしてみた結果が、次の図です。
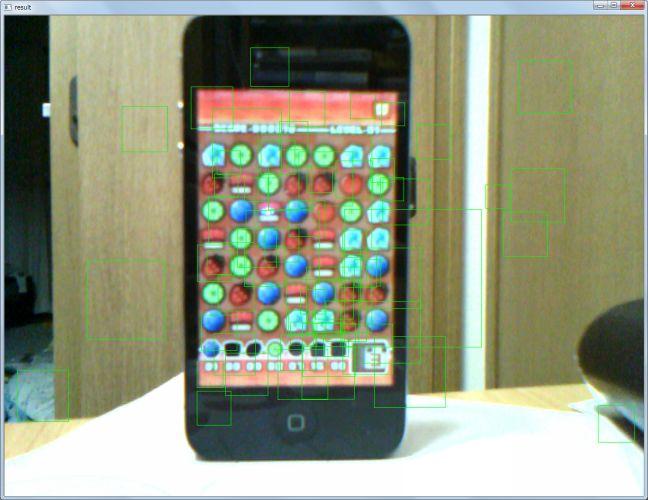
全然あっていないじゃんッ!!! ってな状態です。どうも正解画像のサイズが大きすぎた(検出対象は30×30程度なのに、正解画像が45×45なのがちょっと間違い?)らしくって、検出先の画像は倍のサイズにして検出させました。
OpenCV に入っている haarcascade_frontalface_default.xml を使うと、顔検出ができるのでプログラムのほうは大丈夫らしい。
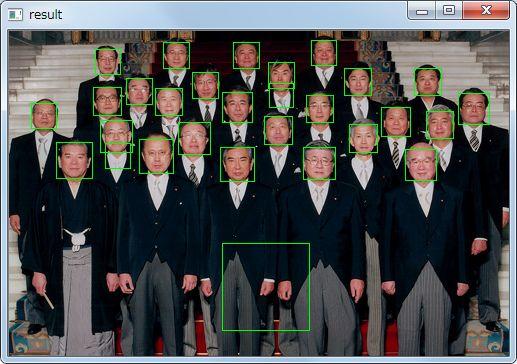
ちなみに、ver.2.3 のほうを使うと、実行時に cv::CascadeClassifier あたりで落ちるので、何故か ver.2.3.1 を使っています。実行時のエラーなので、DLL のビルド間違いとか(リビルドしていないし)かもしれません。
OpenCVによるアニメ顔検出ならlbpcascade_animeface.xml – デー
http://d.hatena.ne.jp/ultraist/20110718/1310965532
anime.udp.jp
http://anime.udp.jp/
探してみると、アニメ絵の顔検出もあって、結構な率で検出できているようです。正解画像を集めて特徴量を抽出してとプラス諸々をやっているそうです。動画のほうの顔検出も結構なスピードで動くので、実行時のスピードは十分ではないかなと。
色特徴によりキャラクター分類なんてのは、他での応用も大きいと思います<エラそうに。
で、自分の実験に話を戻すと、アクションパズルゲームの駒のようなものは、
- そもそも、顔や人型のような「特徴」はない。
- そもそも、ゲームの盤上から、判別すべき「特徴」が浮き出ている。
という特質があります。
最初の「特徴」のほうは、顔とか人型とかの「モデル」ですね。目があるとか口があるとか、それぞれの顔には必要な要素があって、それの要素が個別には少しずつ違う(画像によっては、半分だけとか)ので、これを多数の正解画像(顔の画像)から、共通部分を見つけるというスタイル。
2番目の「特徴」の方は、ゲーム盤面(背景画像)に埋もれないような特徴(色とか輝度とか形)とかが「駒」自体にはあるはずです。でないと、背景に埋もれてしまうし、それは背景ともいえる。背景差分はその手法のひとつで、背景はだいたい止まっているという前提のもとに、動いているもの(オブジェクト)を検出する方法。
で、ゲームの駒というのは、
- ひょっとすると、盤面は動いていないかもしれない。
- ひょっとすると、駒も盤面の動いていないかもしれない。
- でも、明らかに盤面の上に駒がある(将棋の駒とか碁石とかもそう)。
なわけで、もっと大雑把に「特徴」を見極めるのでもよいかな、と昨晩考えていました。
Haar-Like のように細かく画像を調べるのは大袈裟で、もっと大雑把に、
- HSV 画像の色相だけを取り出して、大まかに白黒+6色で特徴量とみなすとか、
- 輝度のヒストグラムを取って、明るい駒と暗い駒を判別するとか、
- 丸っこいとか、四角っぽいとか、ひし形っぽいとか、おおまかな形状で判別するとか、
のような特徴量だけでも十分なのかなと。どうも、駒の特徴量をそのままコーナー検出などに当てはめてしまうと、過学習っぽい気もするし。検出するときにカスケードのルートがひとつしかない(複数のカスケードを使えばそれでいいのでしょうが)のがちょっと気になっています。ひとつの検出器(検出ルール?)を用いるよりも、いくつかの検出器を併用して相互補完するのが誤検出に対しては強いのかなぁと。まだ妄想段階にすぎませんが。

