
以前、ツイートのクローラーを perl で作ってみたのですが、
指定したTwitterアカウントの全ツイートを取得(perl版) | Moonmile Solutions Blog
http://www.moonmile.net/blog/archives/860
この perl スクリプトは古い公式クライアントにしか対応していないので、現在のバージョンではクロールできません…ってな訳で、C# で作り直してみました。
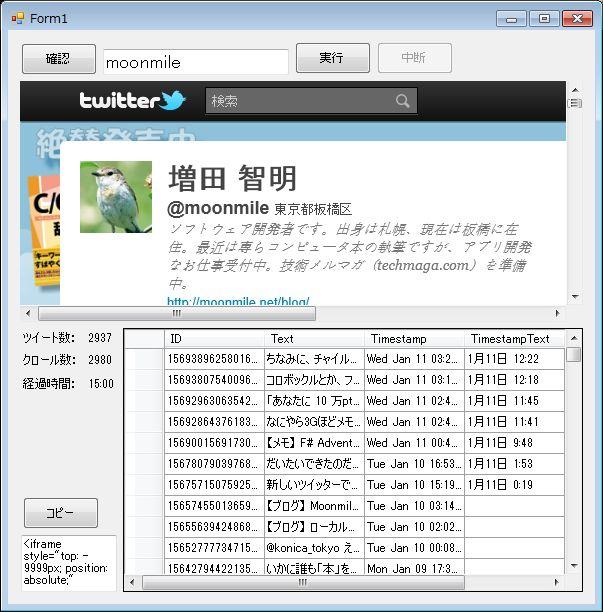
通称「ツイートキャッチ ★★キュア」…★は各自考えるように、とか。
実行ファイルは、CrawlTwitter.0.1.zip をダウンロードしてください。ドキュメントとか一切ないけど、まぁ、暫定版ということで。
ソースコードのほうは、CrawlTwitter at master from moonmile/etc – GitHub にあります。
実行すると結構かかります。3000 ツイートで 15 分ぐらいなので、掛かり過ぎ。これは高速化する予定です。
「コピー」ボタンをクリックすると、グリッドの情報をクリップボードにコピーします。Excel などに貼りつけて使って下さい。
下にあるテキストボックスは、取得したドキュメントのソースですね。デバッグ用に表示しているので、コピーして使ってみてください。中身がわかります。
仕掛けとしては、「もっと見る」のボタン(アンカー)を javascript でクリックしています。C# から WebBrowser オブジェクト経由でクリックする場合は、下記のように
橋本商会 ≫ C#のWebBrowserコンポーネントからJavaScriptを実行
http://shokai.org/blog/archives/1234
ブックマーレットにするといいみたいです。詳しくは git のソースコードを見てください。
—
ちなみに、リンク先の質問に「逆にWebBrowserから情報を得られるのか?」という質問がありますが、ソースコードを見るとわかりますが、
1 | HtmlDocument doc = webBrowser1.Document; |
な形で、ブラウザの DOM が取得できます。これを使うと javascript から dom を使うのと同じように扱えます。なので、javascript 側から値を返す場合は、適当なタグを作っておいて、取り出した HtmlDocument オブジェクトから直接取り出せばいい(getelementbyidとか)のです。


こんにちは。
メッセージボックスで以下のエラーが出て、ツイートの取得ができないのですが、どこをいじればよろしいでしょうか?
——————————————————————————
アプリケーションのコンポーネントで、ハンドルされていない例外が発生しました。[続行]をクリックすると、アプリケーションはこのエラーを無視し、続行しようとします。[終了]をクリックすると、アプリケーションは直ちに終了します。
値をNullにすることはできません。
パラメーター名:data
——————————————————————————
暫定で作ったのでエラー処理をしてなくて、twitter.com の反応が鈍いと取得エラーになって、うまくいかないというのがあるんですよね。なので、「twitter.com」が空いている時間?がお勧めです。
「ツイートの取得」のエラーって、どんな条件でエラーがでますか?
最初の取得をしたときとか、取得をしている途中でエラーが出るとか、そんな風に伝えて頂けると対処しやすいかも。
ご返信ありがとうございます。
アカウントを入力して[実行]を押して待っていても画面下にツイートが表示されないので、
[中断]や[コピー]を押したのですが、
[中断]や[コピー]を押すタイミングでメッセージボックスが現れ、上記のようなメッセージが表示されます。
ですので、ツイートを取得している最中のエラーになるのでしょうか?
1.「確認」ボタンで、アドレスが有効であることを確認
ブラウザに表示される。
2.「実行」ボタンを押すと、クロール数のカウントがアップされるので、ひたすら待つ。
3.「中断」「コピー」は押してはいけません。
「中断」自体は適当な実装だったかも。
そうすると、クロール数が3000ぐらいでストップするはずです…なんですが、止まりませんね。画面の仕様が変わって動かなくなっているのかも。