
テンプレートマッチングで画像から取り出すには無理がありそうなので、やはり、独自なオブジェクト検出器を作ってみないとだめか、と思い、
OpenCVで学ぶ画像認識:第4回 オブジェクト検出器の作成方法|gihyo.jp … 技術評論社
http://gihyo.jp/dev/feature/01/opencv/0004
を読んで、試しに、AdaBoost を使ってカスケードを作ろうと思ったのだが、いやあ、ちょっと時間が掛かりすぎる。
■学習用の正解ファイルの作成
1 2 3 4 5 6 7 | C:\OpenCV2.3\build\bin\opencv_createsamples.exe ^ -img images\koma01.png ^ -vec koma01.vec ^ -num 1000 ^ -bg NG.txt ^ -w 45 -h 45 ^ -show |
■オブジェクトの学習
1 2 3 4 5 6 7 8 | C:\OpenCV2.3\build\bin\opencv_haartraining.exe ^ -data koma01 ^ -vec koma01.vec ^ -bg NG.txt ^ -npos 1000 ^ -nneg 467 ^ -w 45 -h 45 ^ -mem 200 ^ |
な感じで動かしていますが、4時間ほど経っても終わらず。
駒を検出したいので、今回の場合は正解画像は1つ(ゲーム中に出てくる画像)になるのですが、光の関係や画面を映す関係からいくつかの正解画像を用意します。そのあたりは、opencv_createsamples を使って、1000 枚の画像に水増しします。ファイルは別々にできずに、koma01.vec のように1つのファイルにまとめられます。
最初は、駒の画像が 90×90 だったので、そのまま指定したのですが、あえなくメモリーオーバーしてしまい opencv_haartraining がダウン。サイズを 45×45 にすると動くようになったので、対象画像はそこそこ小さいサイズにしないと駄目なのかも。
不正解の画像をどのように集めるのか?とも思ったのですが、マッチングしなければ何でもいいわけで、
Caltech101
http://www.vision.caltech.edu/Image_Datasets/Caltech101/Caltech101.html
にある適当なフォルダ(BACKGROUND_Google というランダムっぽい画像フォルダがある)を使っています。
うまく実行できると、下記のように、(多分)テンプレート画像を切り替えながら、閾値を切り替えながら学習し始めるわけですが…
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 | D:\work\OpenCV\src\PiyoDetect\PiyoML\data>opencv_haartraining.exe -dxml -vec koma01.vec -bg NG.txt -npos 1000 -nneg 467 -w 45 -h 45Data dir name: koma01.xmlVec file name: koma01.vecBG file name: NG.txt, is a vecfile: noNum pos: 1000Num neg: 467Num stages: 14Num splits: 1 (stump as weak classifier)Mem: 200 MBSymmetric: TRUEMin hit rate: 0.995000Max false alarm rate: 0.500000Weight trimming: 0.950000Equal weights: FALSEMode: BASICWidth: 45Height: 45Applied boosting algorithm: GABError (valid only for Discrete and Real AdaBoost): misclassMax number of splits in tree cascade: 0Min number of positive samples per cluster: 500Required leaf false alarm rate: 6.10352e-005Tree ClassifierStage+---+| 0|+---+Number of features used : 1007032Parent node: NULL*** 1 cluster ***POS: 1000 1000 1.000000NEG: 467 1BACKGROUND PROCESSING TIME: 0.22Precalculation time: 0.05+----+----+-+---------+---------+---------+---------+| N |%SMP|F| ST.THR | HR | FA | EXP. ERR|+----+----+-+---------+---------+---------+---------+| 1|100%|-|-0.763750| 1.000000| 1.000000| 0.123381|+----+----+-+---------+---------+---------+---------+| 2|100%|+|-0.660565| 0.999000| 0.837259| 0.123381|+----+----+-+---------+---------+---------+---------+| 3| 94%|-|-1.246627| 0.996000| 0.490364| 0.104294|+----+----+-+---------+---------+---------+---------+Stage training time: 889.36Number of used features: 3Parent node: NULLChosen number of splits: 0Total number of splits: 0Tree ClassifierStage+---+| 0|+---+ 0Parent node: 0*** 1 cluster ***POS: 996 1000 0.996000NEG: 465 0.524831BACKGROUND PROCESSING TIME: 0.03Precalculation time: 0.05+----+----+-+---------+---------+---------+---------+| N |%SMP|F| ST.THR | HR | FA | EXP. ERR|+----+----+-+---------+---------+---------+---------+| 1|100%|-|-0.635385| 1.000000| 1.000000| 0.182752|+----+----+-+---------+---------+---------+---------+| 2|100%|+|-0.333012| 0.996988| 0.544086| 0.149213|+----+----+-+---------+---------+---------+---------+| 3|100%|-|-0.999921| 0.996988| 0.544086| 0.082820|+----+----+-+---------+---------+---------+---------+| 4|100%|+|-0.692312| 0.996988| 0.389247| 0.063655|+----+----+-+---------+---------+---------+---------+Stage training time: 1205.64Number of used features: 4Parent node: 0Chosen number of splits: 0Total number of splits: 0Tree ClassifierStage+---+---+| 0| 1|+---+---+ 0---1Parent node: 1*** 1 cluster ***POS: 993 1000 0.993000NEG: 463 0.230923BACKGROUND PROCESSING TIME: 0.13Precalculation time: 0.05+----+----+-+---------+---------+---------+---------+| N |%SMP|F| ST.THR | HR | FA | EXP. ERR|+----+----+-+---------+---------+---------+---------+| 1|100%|-|-0.912574| 1.000000| 1.000000| 0.160027|+----+----+-+---------+---------+---------+---------+| 2|100%|+|-1.372380| 1.000000| 1.000000| 0.298077|+----+----+-+---------+---------+---------+---------+| 3|100%|-|-1.029186| 1.000000| 1.000000| 0.073489|+----+----+-+---------+---------+---------+---------+| 4|100%|+|-1.168364| 0.996979| 0.796976| 0.073489|+----+----+-+---------+---------+---------+---------+| 5| 98%|-|-0.856654| 0.996979| 0.455724| 0.049451|+----+----+-+---------+---------+---------+---------+Stage training time: 1487.86Number of used features: 5Parent node: 1Chosen number of splits: 0Total number of splits: 0Tree ClassifierStage+---+---+---+| 0| 1| 2|+---+---+---+ 0---1---2Parent node: 2*** 1 cluster ***POS: 990 1000 0.990000NEG: 462 0.1232BACKGROUND PROCESSING TIME: 0.53Precalculation time: 0.05+----+----+-+---------+---------+---------+---------+| N |%SMP|F| ST.THR | HR | FA | EXP. ERR|+----+----+-+---------+---------+---------+---------+| 1|100%|-|-0.606609| 1.000000| 1.000000| 0.199036|+----+----+-+---------+---------+---------+---------+| 2|100%|+|-0.848618| 1.000000| 1.000000| 0.199036|+----+----+-+---------+---------+---------+---------+| 3|100%|-|-0.527684| 0.996970| 0.614719| 0.152204|+----+----+-+---------+---------+---------+---------+| 4|100%|+|-0.781167| 0.996970| 0.623377| 0.154959|+----+----+-+---------+---------+---------+---------+| 5| 79%|-|-1.579804| 0.997980| 0.632035| 0.112948| |
そもそもの目的が、ゲーム画面から既知の駒(時には未知の駒?)を見つけ出したいわけで、顔認識ほど正確でなくてもよいし、ある程度の場所を確定してから再マッチさせるという方式がやっぱりよさそうか、と思い直している次第です。
OpenCVで学ぶ画像認識:第3回 オブジェクト検出してみよう|gihyo.jp … 技術評論社
http://gihyo.jp/dev/feature/01/opencv/0003?page=2
にあるように、何もないところから特定のものを見つける(検出する率が低い)場合には、このような学習がよいのかもしれませんが、あらかじめ駒があるとわかっているゲームの盤上から探すには、もっと前処理をして絞り込んでもよいかなと。オブジェクト検出器の中で Ture/False の判断をするよりも、その前処理として Ture/False を大雑把に判断するロジックを挟む必要がありそうです。いちいち、駒の形状が変わるたびに、学習をさせるわけにはいかないし、学習自体にそれほど時間を掛ける意味はなさそうだし。
なので、決定木あたりかクラスタリングを使って、駒のツリー(今回は8種類程度だけど)を作るのがよいのでしょう。
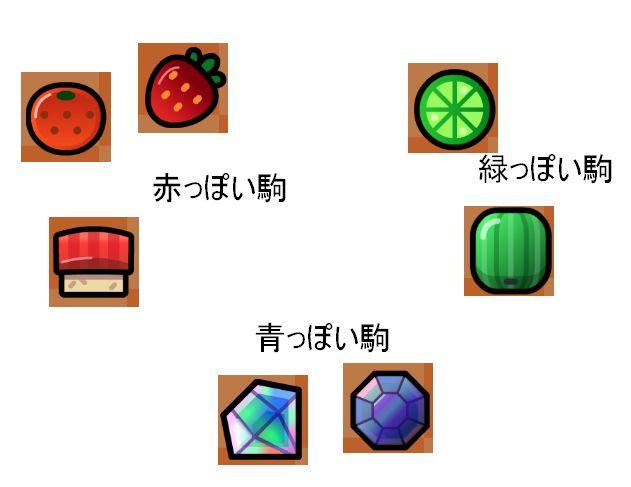
のように、色味で分割で大雑把に分割ができるのは明らかなので、なんらかの特徴量を元に背景画像から抜き出した後に、相互に駒を判断するために再び特徴量を使うという2段階になるのでしょう。
そんな訳でオライリーの OpenCV を再読。

