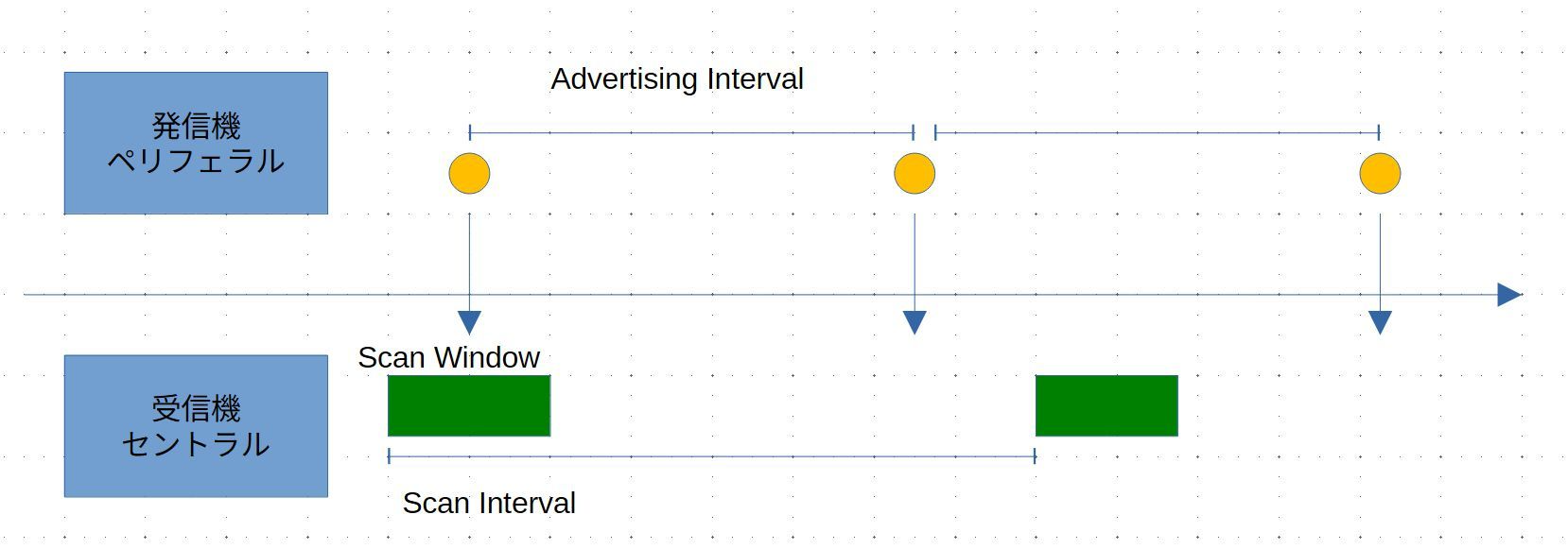
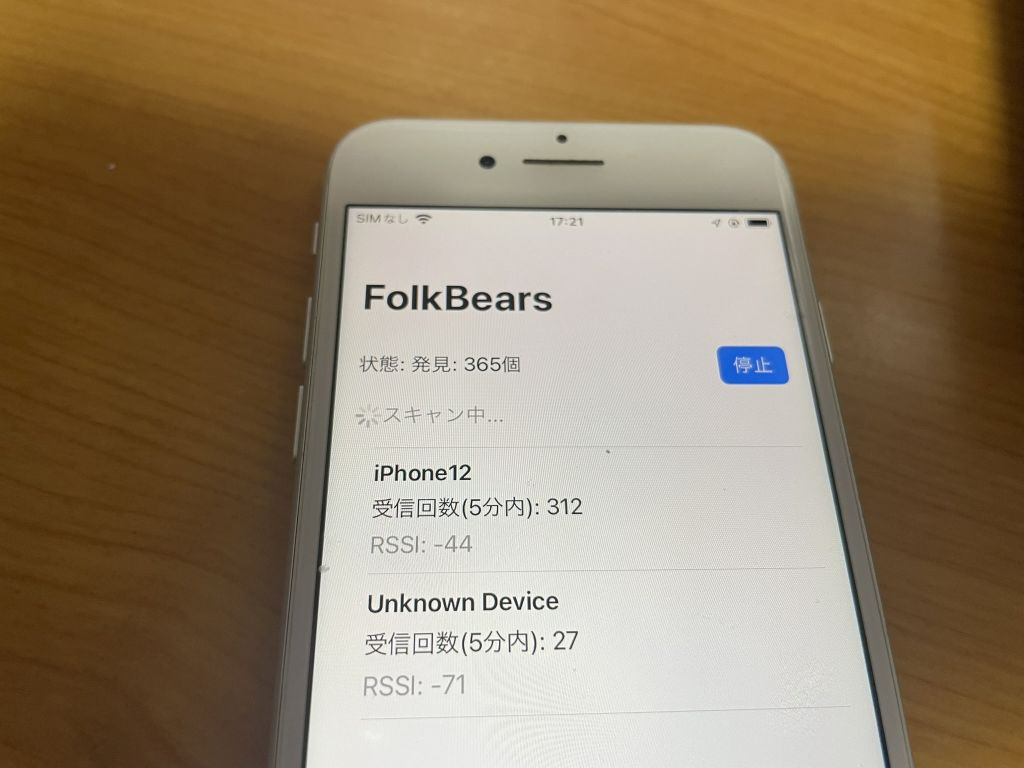
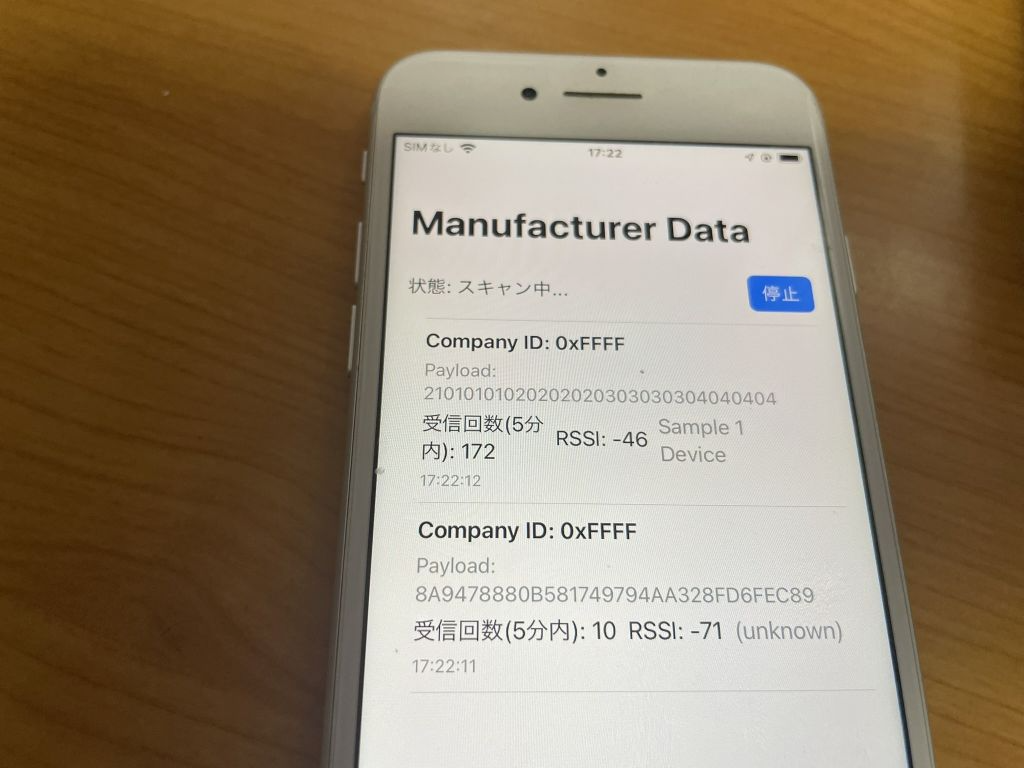
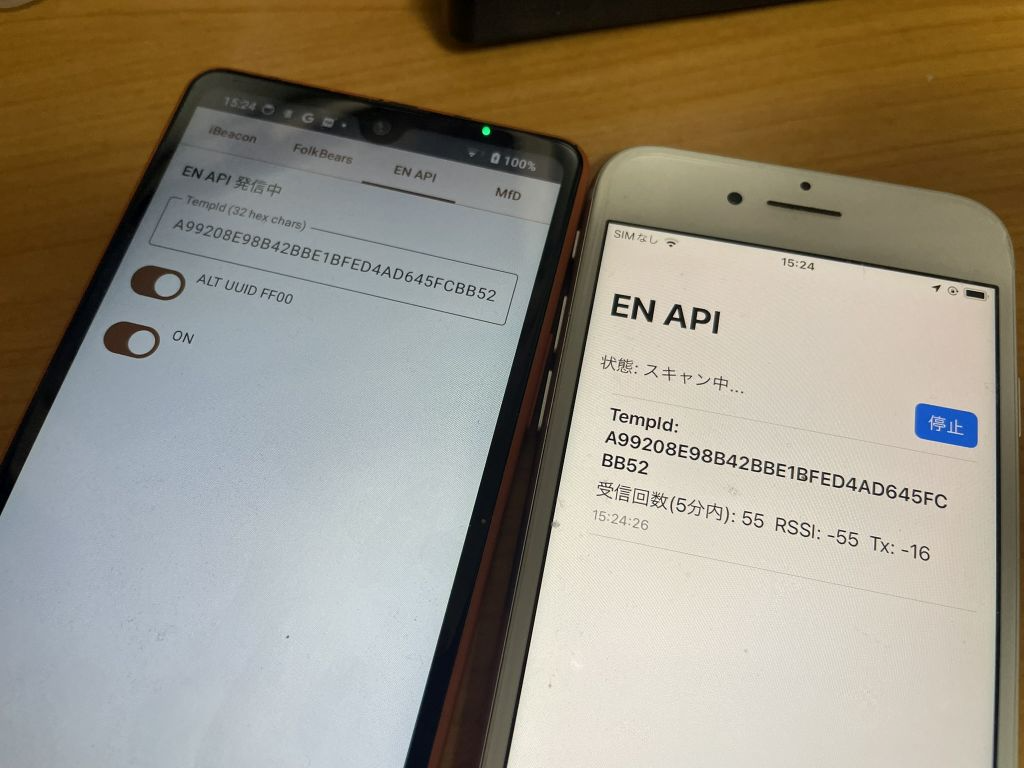
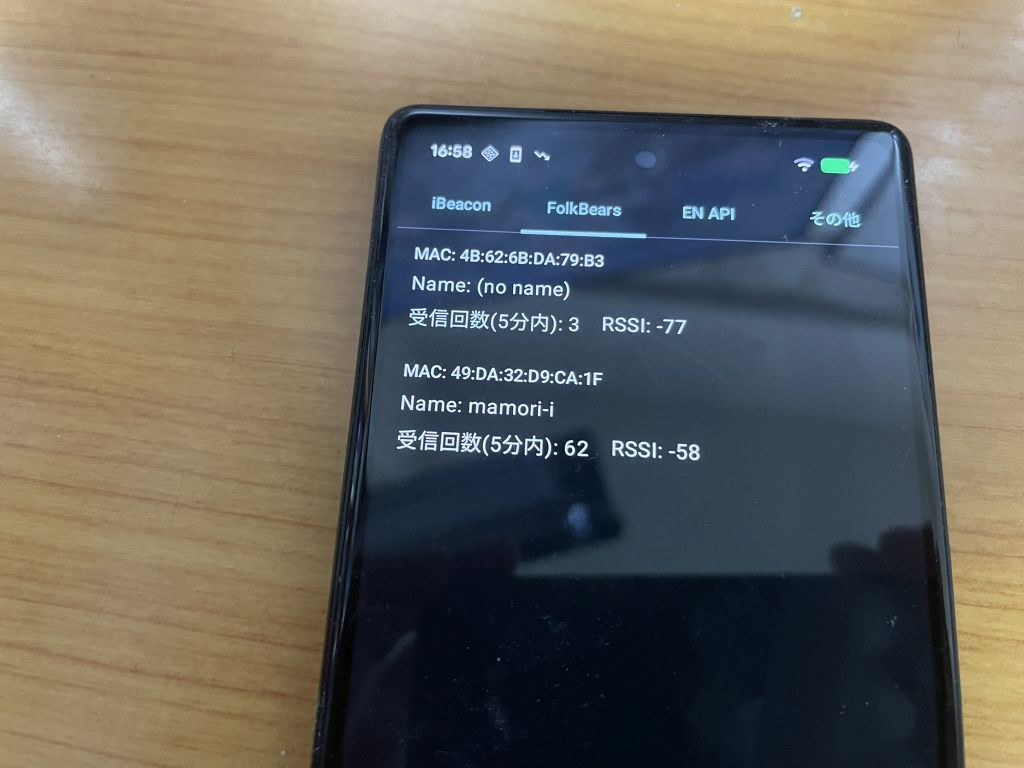
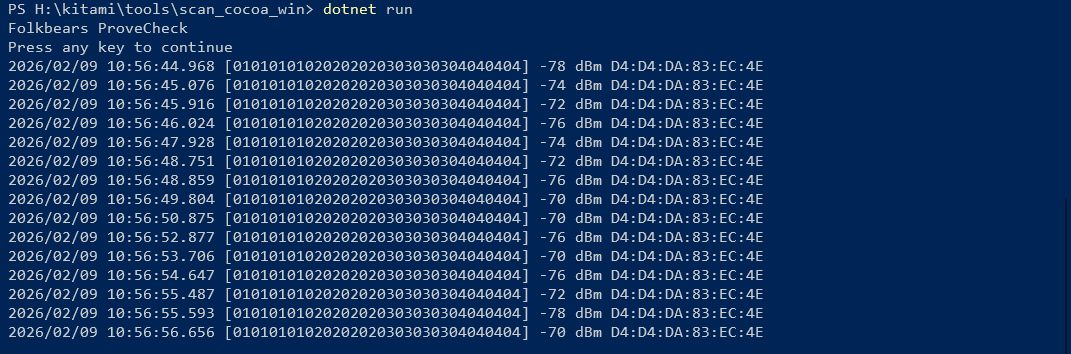
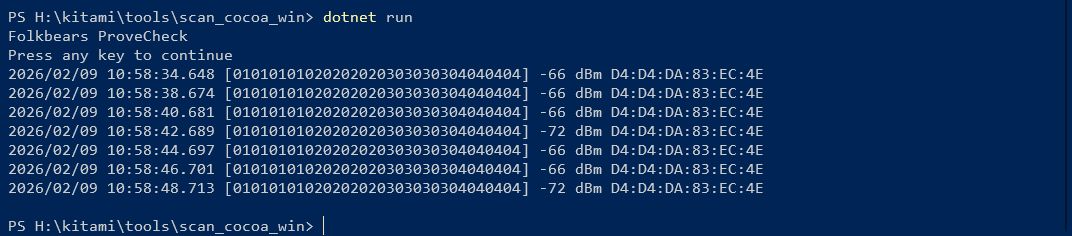
接触確認アプリでは Android/iOS の相互で BLE 通信を行うために、iOS での発信機のチェックもしておきます。 iOS の場合は、16 bit Service UUID 形式と Manufacturer Data 形式では発信できません。が、”発信できないこと” を確認するために、あえて両方の実装もしてあります。実際に iOS/Android の受信機で受信ができないことを確認してください。
EN API 形式の発信は、16 bit Service UUID を指定して発信するパターンですが、iOS では送信できません。送信はできないのですが、確認のためにコードは作ってあります。Android の受信機で受信できないことを確認してください。 たまに、Android/iOS の受信機に到達することがあり(このときのアドバタイズデータはランダム値になっています)、微妙な感じがするのですが、使えないのは確かです。
class ENSimTransmitter: NSObject, ObservableObject {
private var peripheralManager: CBPeripheralManager?
private let serviceUUID = CBUUID(string: "FD6F") // Exposure Notification 16-bit UUID
private let altServiceUUID = CBUUID(string: "FF00") // Alternative UUID for testing
@Published var isTransmitting = false
@Published var transmissionStatus = "停止中"
@Published var bluetoothState = "Unknown"
@Published var localName = "ENSim"
@Published var useAltService: Bool = false
@Published var rpi: Data = ENSimTransmitter.generateRandomRpi()
override init() {
super.init()
setupPeripheralManager()
}
private func setupPeripheralManager() {
peripheralManager = CBPeripheralManager(delegate: self, queue: nil)
}
func startTransmitting() {
guard let manager = peripheralManager else {
print("PeripheralManager が初期化されていません")
return
}
guard manager.state == .poweredOn else {
print("Bluetooth が利用できません (state: \(manager.state.rawValue))")
return
}
guard !isTransmitting else {
print("既にアドバタイズ中です")
return
}
let selectedService = useAltService ? altServiceUUID : serviceUUID
let serviceData: [CBUUID: Data] = [selectedService: rpi]
let advertisementData: [String: Any] = [
CBAdvertisementDataServiceUUIDsKey: [selectedService],
CBAdvertisementDataLocalNameKey: localName,
// CBAdvertisementDataServiceDataKey: serviceData
]
manager.startAdvertising(advertisementData)
isTransmitting = true
transmissionStatus = "発信中..."
print("📡 EN シミュレーション発信開始")
print(" Service UUID (16-bit): \(useAltService ? altServiceUUID.uuidString : serviceUUID.uuidString)")
print(" Local Name: \(localName)")
print(" RPI (hex): \(rpi.map { String(format: "%02X", $0) }.joined())")
}
func stopTransmitting() {
guard let manager = peripheralManager, isTransmitting else { return }
manager.stopAdvertising()
isTransmitting = false
transmissionStatus = "停止中"
print("EN シミュレーション発信停止")
}
private static func generateRandomRpi() -> Data {
// let bytes = (0..<16).map { _ in UInt8.random(in: 0...255) }
// ランダムな uuid を生成して RPI として使用(デバッグ用)
// 送信は成功するが、Service Data の内容はランダム値になってしまうので、
// 実質利用ができない。
let uuid = UUID()
let uuidBytes = withUnsafeBytes(of: uuid.uuid) { Array($0) }
let bytes = Array(uuidBytes.prefix(16))
return Data(bytes)
}
}
Manufacturer Data 形式の発信
自由な形式でデータをブロードキャストする場合は、Manufacturer Data 形式で発信するのが一番いいのですが、これも iOS では使えません。これも、使えないことを確認するためにコードを作ってあります。 先に書いた通り、startAdvertisingRawIBeacon 関数を作ってもデータは送信できません。
/// Advertises custom manufacturer data (often consumed as scan response data on the scanner side).
/// フォーマット: [0]=0x02 (type), [1]=0x10 (length=16), [2..17]=TempId(16byte)
class ManufacturerDataTransmitter: NSObject, ObservableObject {
private var peripheralManager: CBPeripheralManager?
@Published var isTransmitting = false
@Published var transmissionStatus = "停止中"
@Published var bluetoothState = "Unknown"
@Published var localName: String = "MFG"
/// 16-bit company identifier (Little Endian in the payload). Default: 0xFFFF for testing.
@Published var companyId: UInt16 = 0xFFFF
let beacon_type = 0x02
let beacon_length = 0x10
/// Arbitrary manufacturer payload. Default 16 zero bytes for easy overriding.
@Published var tempIdBytes: Data = Data(repeating: 0x00, count: 16)
/// Last advertisement dictionary for debugging.
private(set) var lastAdvertisementData: [String: Any]? = nil
override init() {
super.init()
setupPeripheralManager()
}
private func setupPeripheralManager() {
peripheralManager = CBPeripheralManager(delegate: self, queue: nil)
}
/// Start advertising manufacturer data. Uses CBAdvertisementDataManufacturerDataKey which may appear in scan response on the scanner side depending on size and platform rules.
func startTransmitting() {
guard let manager = peripheralManager else {
print("PeripheralManager が初期化されていません")
return
}
guard manager.state == .poweredOn else {
print("Bluetooth が利用できません (state: \(manager.state.rawValue))")
return
}
guard !isTransmitting else {
print("既にアドバタイズ中です")
return
}
// Build manufacturer data: company ID (little endian) + payload.
var mfgData = Data()
mfgData.append(UInt8(companyId & 0xFF))
mfgData.append(UInt8((companyId >> 8) & 0xFF))
mfgData.append(UInt8(beacon_type))
mfgData.append(UInt8(beacon_length))
mfgData.append(tempIdBytes)
let advertisementData: [String: Any] = [
CBAdvertisementDataManufacturerDataKey: mfgData,
CBAdvertisementDataLocalNameKey: localName
]
lastAdvertisementData = advertisementData
manager.startAdvertising(advertisementData)
isTransmitting = true
transmissionStatus = "発信中..."
print("📡 Manufacturer 発信開始")
print(String(format: " Company ID: 0x%04X (LE)", companyId))
print(" tempIdBytes (hex): \(tempIdBytes.map { String(format: "%02X", $0) }.joined())")
print(" Local Name: \(localName)")
}
func stopTransmitting() {
guard let manager = peripheralManager, isTransmitting else { return }
manager.stopAdvertising()
isTransmitting = false
transmissionStatus = "停止中"
print("Manufacturer 発信停止")
}
}
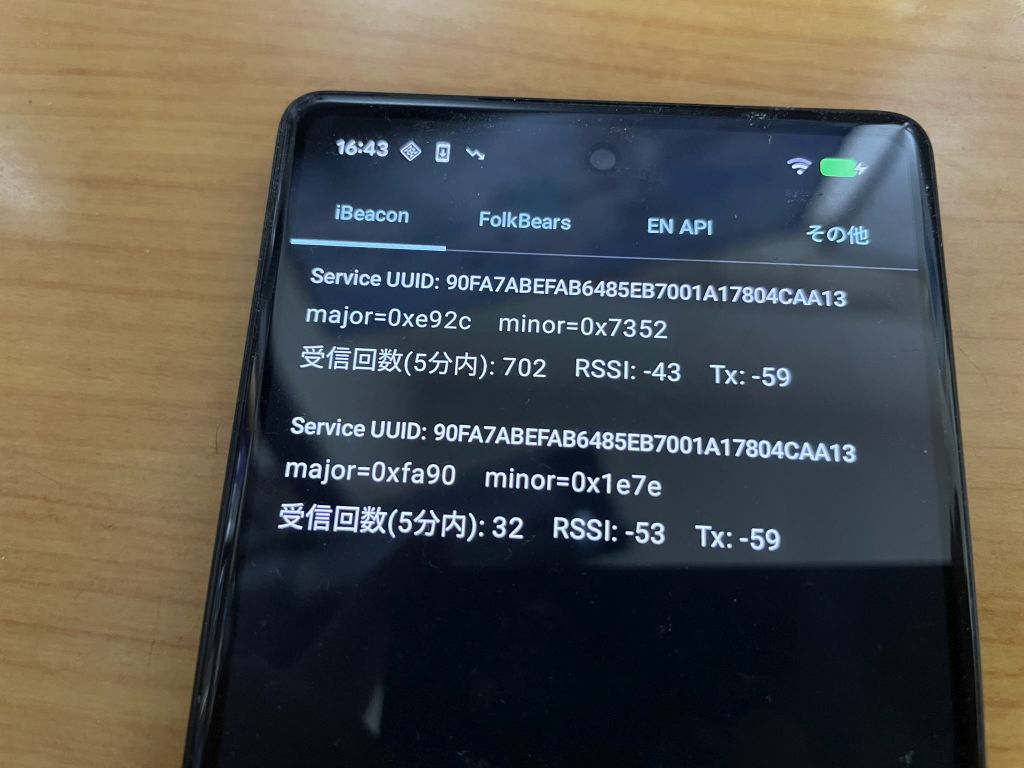
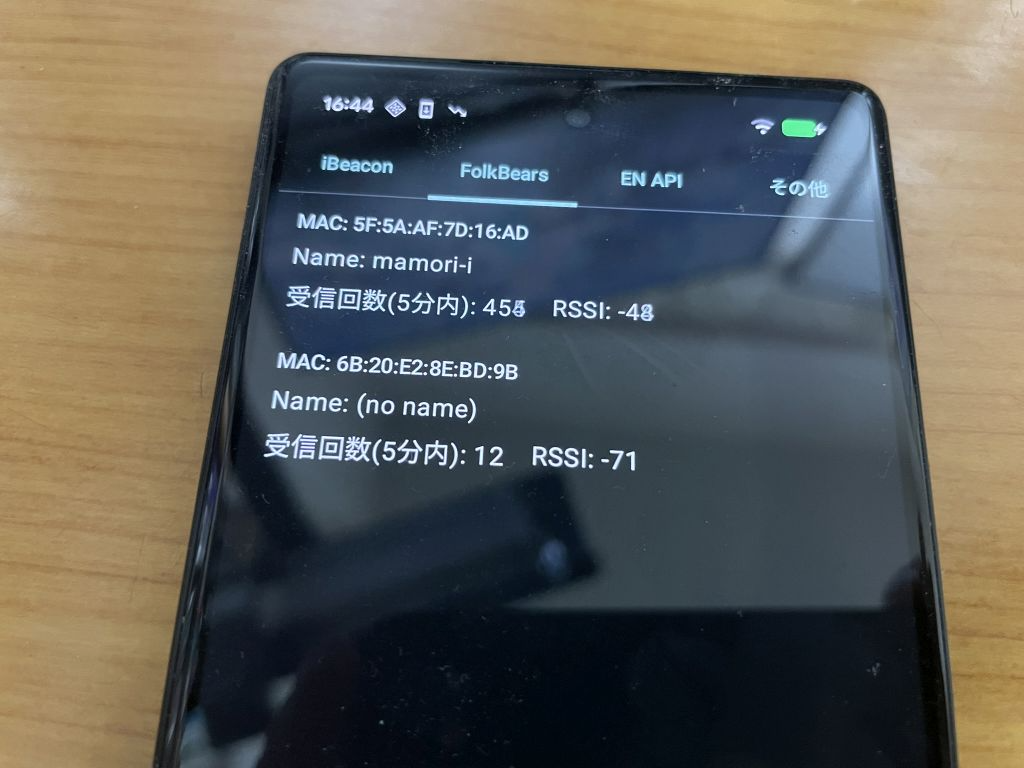
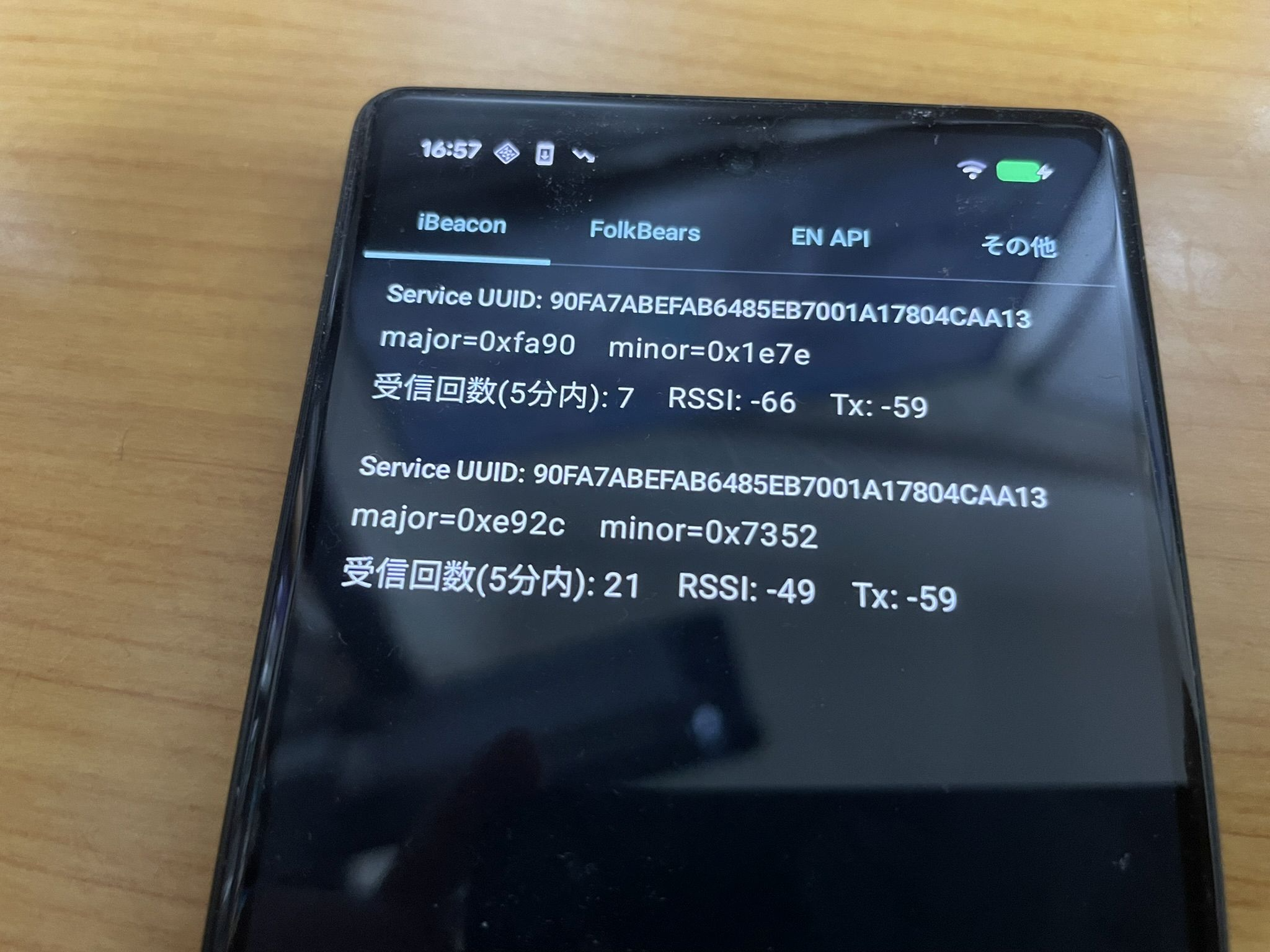
実行
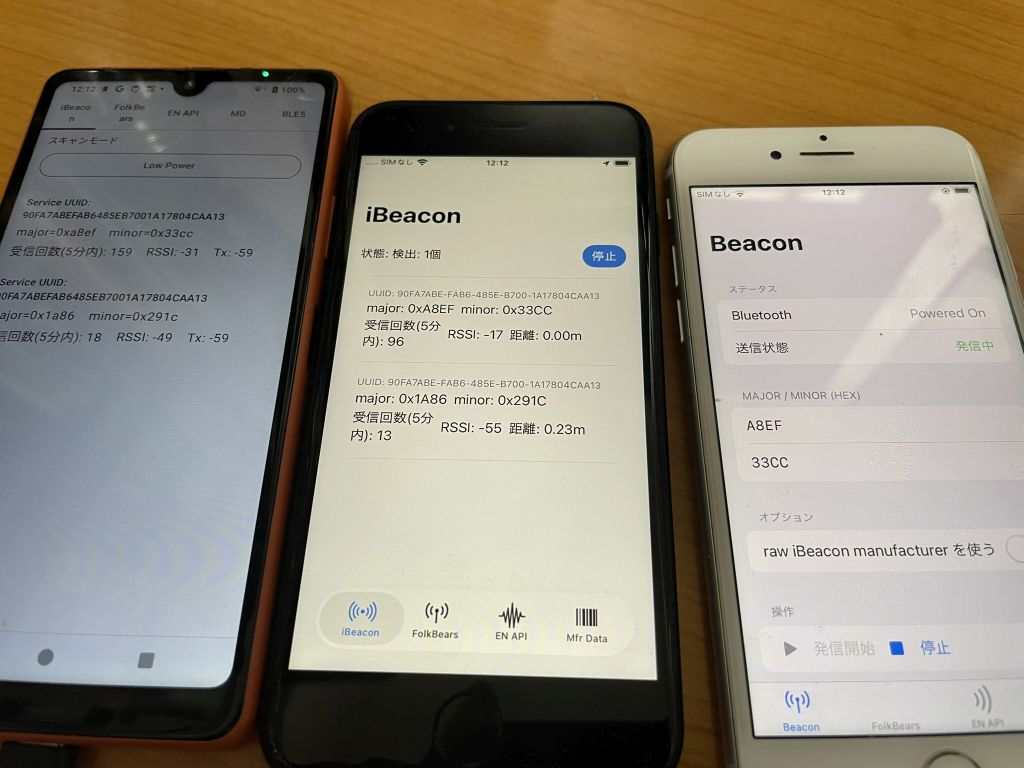
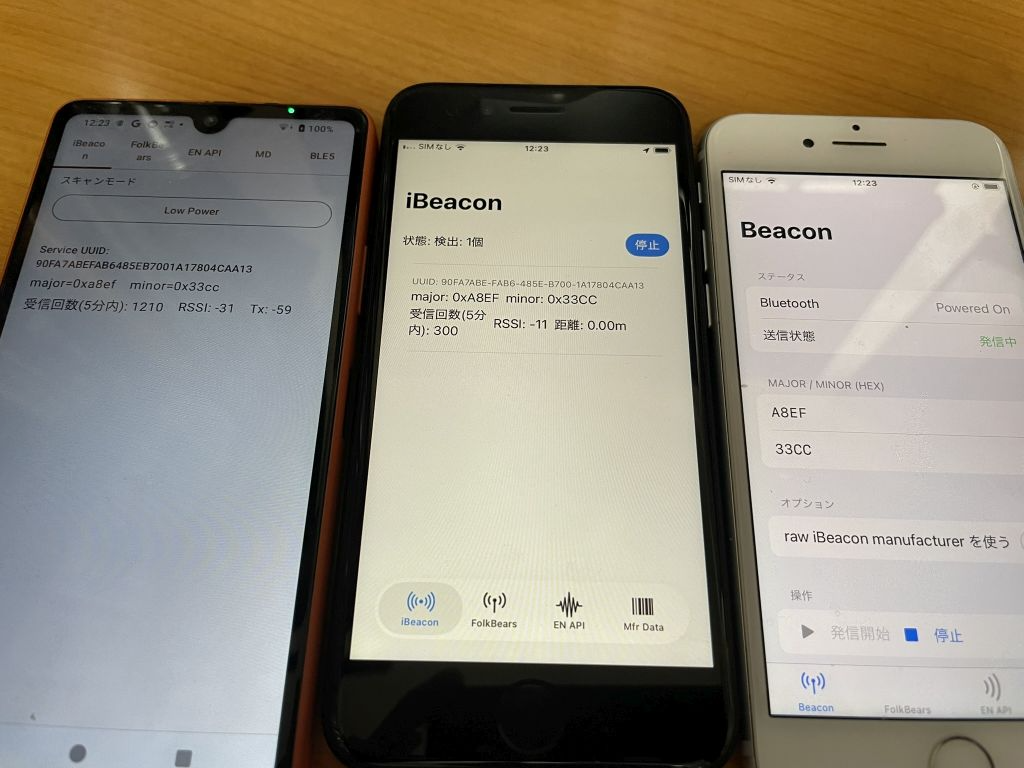
左から
Android で受信
iPhone で受信
iPhone で発信
という状態です。iBeacon の UUID は同じなので、major と minor で判断をします。
class BeaconTransmitter(
private val context: Context,
major: Int = 0,
minor: Int = 0
) {
companion object {
const val TAG = "BeaconTransmitter"
val SERVICE_UUID: UUID = UUID.fromString("90FA7ABE-FAB6-485E-B700-1A17804CAA13") // FolkBears サービス
}
private var beaconTransmitter: org.altbeacon.beacon.BeaconTransmitter? = null
var major: Int = major
var minor: Int = minor
var advertiseMode: Int = AdvertiseSettings.ADVERTISE_MODE_LOW_POWER
var advertiseTxPowerLevel: Int = AdvertiseSettings.ADVERTISE_TX_POWER_LOW
private fun startBeaconTransmission() {
// Permission check (Android 12+ requires BLUETOOTH_ADVERTISE)
val advertiseGranted = ContextCompat.checkSelfPermission(
context,
android.Manifest.permission.BLUETOOTH_ADVERTISE
) == android.content.pm.PackageManager.PERMISSION_GRANTED
if (!advertiseGranted) {
Log.e(TAG, "BLUETOOTH_ADVERTISE permission not granted; cannot start advertising")
return
}
val adapter = BluetoothAdapter.getDefaultAdapter()
if (adapter == null) {
Log.e(TAG, "BluetoothAdapter not available")
return
}
if (!adapter.isEnabled) {
Log.e(TAG, "BluetoothAdapter disabled; enable Bluetooth and retry")
return
}
// 以下 org.altbeacon.beacon を利用しない方法も検討
val support = org.altbeacon.beacon.BeaconTransmitter.checkTransmissionSupported(context)
if (support != org.altbeacon.beacon.BeaconTransmitter.SUPPORTED) {
Log.e(TAG, "Beacon transmission not supported: code=$support")
return
}
val beacon = Beacon.Builder()
.setId1(SERVICE_UUID.toString()) // UUID
.setId2(major.toString()) // Major (10進数文字列)
.setId3(minor.toString()) // Minor (10進数文字列)
.setManufacturer(0x004C) // Apple iBeacon のメーカーコード
.setTxPower(-59) // 信号強度 (dBm)は仮設定
.build()
// val beaconParser = BeaconParser().setBeaconLayout(BeaconParser.ALTBEACON_LAYOUT)
val beaconParser = BeaconParser().setBeaconLayout("m:2-3=0215,i:4-19,i:20-21,i:22-23,p:24-24")
val altBeaconTransmitter = BeaconTransmitter(context, beaconParser).apply {
advertiseMode = this@BeaconTransmitter.advertiseMode
advertiseTxPowerLevel = this@BeaconTransmitter.advertiseTxPowerLevel
isConnectable = false // 非コネクタブルに
}
try {
altBeaconTransmitter?.startAdvertising(beacon, object : AdvertiseCallback() {
override fun onStartSuccess(settingsInEffect: AdvertiseSettings) {
Log.d(TAG, "iBeacon 発信開始")
}
override fun onStartFailure(errorCode: Int) {
Log.e(TAG, "iBeacon 発信に失敗: $errorCode")
}
})
} catch (e: SecurityException) {
Log.e(TAG, "SecurityException when starting advertising: ${e.message}")
} catch (e: Throwable) {
Log.e(TAG, "Unexpected error when starting advertising: ${e.message}")
}
}
///
/// @break Beacon の発信開始
///
fun startTransmitter() {
Log.d(TAG, "startTransmitter")
if (beaconTransmitter == null ) {
startBeaconTransmission()
}
}
///
/// @brief Beacon の発信停止
///
fun stopTransmitter() {
Log.d(TAG, "stopTransmitter")
beaconTransmitter?.stopAdvertising()
beaconTransmitter = null
}
}
EN API 形式の発信
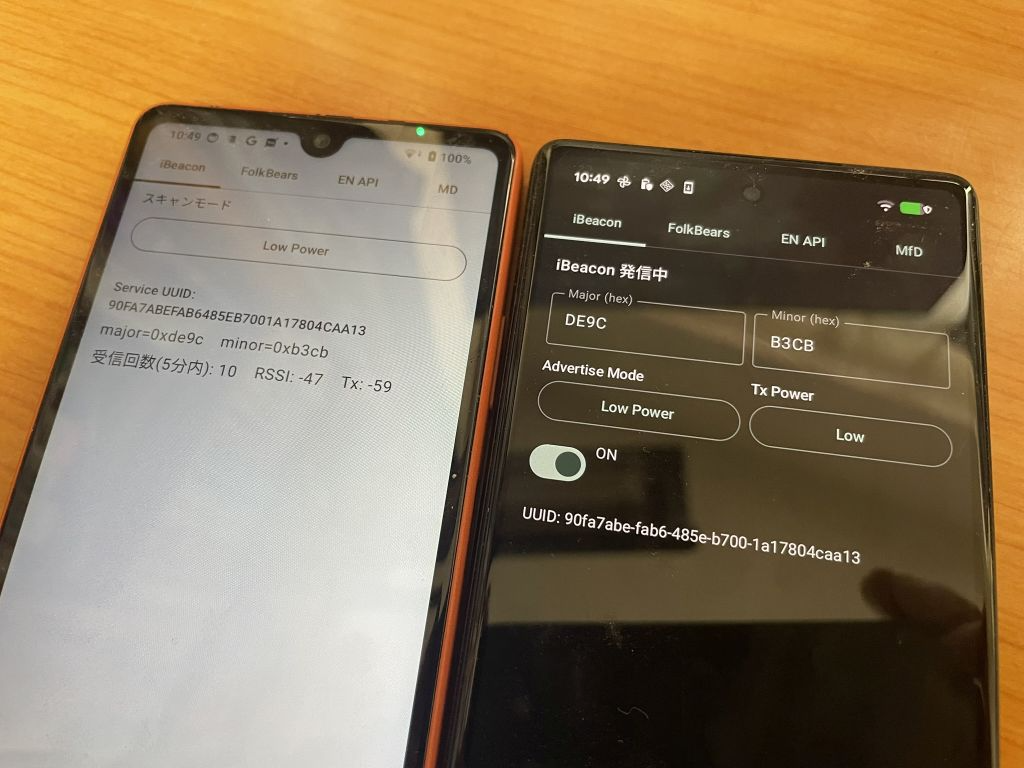
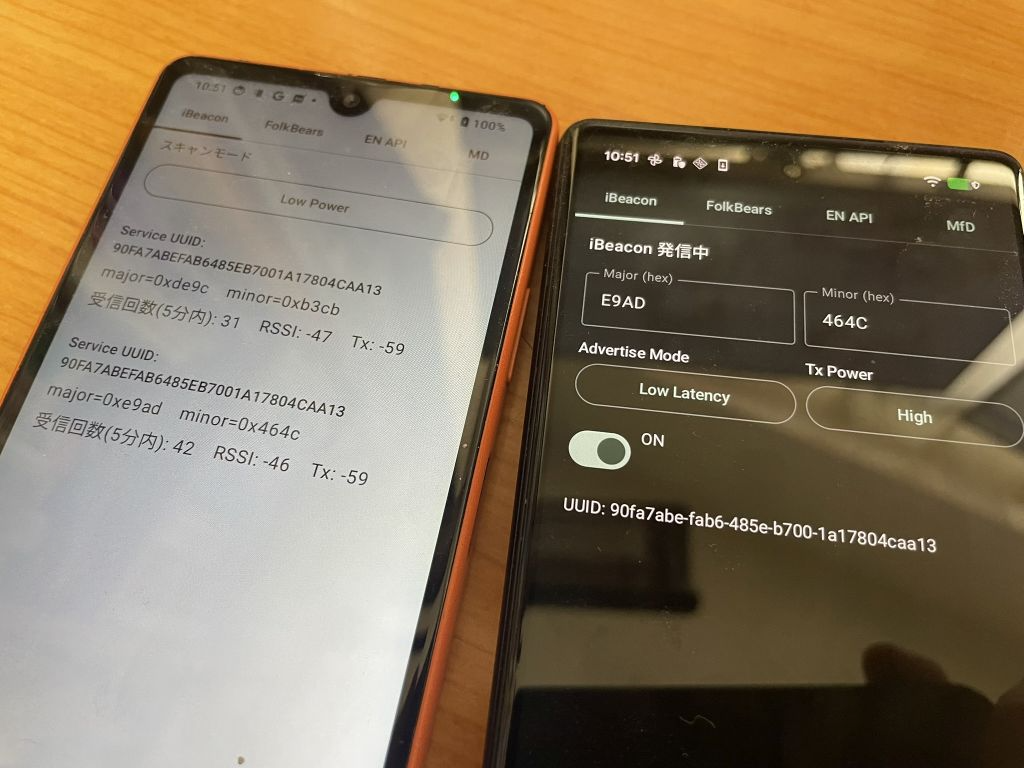
EN API 形式の発信は、16 bit Service UUID を指定して発信するパターンです。BluetoothLeAdvertiser を使います。 EN API の 0xFD6F と実験用の 0xFF00 のどちらかで送信できるようにします。 Android の場合は 0xFD6F も 0xFF00 も両方とも受信できます。iOS の場合は 0xFF00 のほうだけが受信できます。
class ENSimTransmitter(
private val context: Context,
tempIdBytes: ByteArray = ByteArray(16),
useAltService: Boolean = false
) {
companion object {
const val TAG = "ENSimTransmitter"
val SERVICE_UUID: UUID = UUID.fromString("0000FD6F-0000-1000-8000-00805F9B34FB")
val SERVICE_UUID_ALT: UUID = UUID.fromString("0000FF00-0000-1000-8000-00805F9B34FB")
val SERVICE_DATA_UUID_ALT: UUID = UUID.fromString("00000001-0000-1000-8000-00805F9B34FB")
}
var useAltService: Boolean = useAltService
var tempIdBytes: ByteArray = tempIdBytes
var advertiseMode: Int = AdvertiseSettings.ADVERTISE_MODE_LOW_POWER
var advertiseTxPowerLevel: Int = AdvertiseSettings.ADVERTISE_TX_POWER_LOW
private var advertiser: BluetoothLeAdvertiser? = null
private var advertiseCallback: AdvertiseCallback? = null
@Volatile
private var isAdvertising = false
///
/// ENSim の発信開始
///
fun startTransmitter() {
Log.d(TAG, "startTransmitter")
startAdvertisingInternal()
}
///
/// ENSim の発信停止
///
fun stopTransmitter() {
Log.d(TAG, "stopTransmitter")
advertiser?.stopAdvertising(advertiseCallback)
}
private fun startAdvertisingInternal() {
if ( advertiser == null ) {
val bluetoothManager = context.getSystemService(Context.BLUETOOTH_SERVICE) as BluetoothManager
val adapter = bluetoothManager.adapter
advertiser = adapter.bluetoothLeAdvertiser
}
val adv = advertiser ?: run {
Log.e(TAG, "BluetoothLeAdvertiser を取得できませんでした")
return
}
val settings = AdvertiseSettings.Builder()
.setAdvertiseMode(advertiseMode)
.setTxPowerLevel(advertiseTxPowerLevel)
.setConnectable(false)
.build()
val targetUuid = if (useAltService) SERVICE_UUID_ALT else SERVICE_UUID
val dataUuidForPayload = if (useAltService) SERVICE_DATA_UUID_ALT else targetUuid
val data = AdvertiseData.Builder()
.setIncludeDeviceName(false)
.setIncludeTxPowerLevel(true)
.addServiceUuid(ParcelUuid(targetUuid))
.addServiceData(ParcelUuid(dataUuidForPayload), tempIdBytes)
.build()
advertiseCallback = object : AdvertiseCallback() {
override fun onStartSuccess(settingsInEffect: AdvertiseSettings) {
super.onStartSuccess(settingsInEffect)
isAdvertising = true
Log.d(TAG, "ENSim advertise start")
}
override fun onStartFailure(errorCode: Int) {
super.onStartFailure(errorCode)
isAdvertising = false
Log.e(TAG, "ENSim advertise failed: $errorCode")
}
}
try {
adv.startAdvertising(settings, data, advertiseCallback)
} catch (e: Exception) {
isAdvertising = false
Log.e(TAG, "startAdvertising exception: ${e.message}")
}
}
private fun String.toByteArrayFromHex(): ByteArray {
if (length % 2 != 0) return ByteArray(0)
return chunked(2)
.mapNotNull { it.toIntOrNull(16)?.toByte() }
.toByteArray()
}
}
class GattAdvertise(
private val context: Context
)
{
companion object {
const val TAG = "GattAdvertise"
val SERVICE_UUID: UUID = UUID.fromString("90FA7ABE-FAB6-485E-B700-1A17804CAA13") // FolkBears サービス
}
private var advertiser: BluetoothLeAdvertiser? = null
@Volatile
var isAdvertising = false
private var lastStopTime = 0L
private var backgroundRetryRunnable: Runnable? = null
var advertiseMode: Int = AdvertiseSettings.ADVERTISE_MODE_LOW_POWER
var advertiseTxPowerLevel: Int = AdvertiseSettings.ADVERTISE_TX_POWER_LOW
private var currentCallback: AdvertiseCallback? = null
private fun createAdvertiseCallback(): AdvertiseCallback {
return object : AdvertiseCallback() {
override fun onStartSuccess(settingsInEffect: AdvertiseSettings) {
super.onStartSuccess(settingsInEffect)
Log.d(TAG, "Advertising onStartSuccess")
isAdvertising = true
}
override fun onStartFailure(errorCode: Int) {
super.onStartFailure(errorCode)
val reason: String
when (errorCode) {
ADVERTISE_FAILED_ALREADY_STARTED -> {
Log.w(TAG, "Advertising already started on Android ${Build.VERSION.SDK_INT}, forcing stop and retry")
return
}
ADVERTISE_FAILED_FEATURE_UNSUPPORTED -> {
reason = "ADVERTISE_FAILED_FEATURE_UNSUPPORTED"
isAdvertising = false
}
ADVERTISE_FAILED_INTERNAL_ERROR -> {
reason = "ADVERTISE_FAILED_INTERNAL_ERROR"
isAdvertising = false
}
ADVERTISE_FAILED_TOO_MANY_ADVERTISERS -> {
reason = "ADVERTISE_FAILED_TOO_MANY_ADVERTISERS"
isAdvertising = false
}
ADVERTISE_FAILED_DATA_TOO_LARGE -> {
reason = "ADVERTISE_FAILED_DATA_TOO_LARGE"
isAdvertising = false
}
else -> {
reason = "UNDOCUMENTED"
isAdvertising = false
}
}
Log.d(TAG, "Advertising onStartFailure: $errorCode - $reason")
}
}
}
private var data: AdvertiseData? = null
fun startAdvertising() {
if ( advertiser == null ) {
val bluetoothManager = context.getSystemService(Context.BLUETOOTH_SERVICE) as BluetoothManager
val adapter = bluetoothManager.adapter
advertiser = adapter.bluetoothLeAdvertiser
}
if (isAdvertising) {
Log.d(TAG, "Already advertising or starting: advertising=$isAdvertising")
return
}
data = AdvertiseData.Builder()
.setIncludeDeviceName(false)
.setIncludeTxPowerLevel(true)
.addServiceUuid(ParcelUuid(SERVICE_UUID))
.build()
currentCallback = createAdvertiseCallback()
val settings = AdvertiseSettings.Builder()
.setTxPowerLevel(advertiseTxPowerLevel)
.setAdvertiseMode(advertiseMode)
.setConnectable(true)
.build()
advertiser?.startAdvertising(settings, data, currentCallback)
}
fun stopAdvertising() {
if ( isAdvertising == false ) {
Log.d(TAG, "Not currently advertising, skipping stop")
return
}
currentCallback?.let { advertiser?.stopAdvertising(it) }
isAdvertising = false
}
}
Manufacturer Data 形式の発信
自由な型式でデータをブロードキャストする場合は、Manufacturer Data 形式で発信するのが一番いいのです。Manufacturer Data 形式の場合は、Android でも iOS でも受信が可能です。 ただし、iOS の場合は、Manufacturer Data 形式での発信ができないので、接触確認アプリ FolkBears の作成には向いていません…が、m5stack などの専用デバイスを作れば結構いけるのではないか、と思っています。その場合は、16 bit Service UUID を使う方法もあるのですが。
COCOA/EN API のように特定のデータを配信する形は、この Manufacturer Data 形式でやるのが一番いいのですが、後で記事にしますが iOS では Manufacturer Data での発信ができません。Manufacturer Data 形式で発信できるのは iBeacon 形式だけで、実際に発信しようとするとデータ部分がランダム値(?)になってしまうことになります。これは、実際に iOS 用の発信ツールを作ったときに確認します。
final class ManufacturerDataScan: NSObject, ObservableObject {
/// 受信時のコールバック。keyはCompany ID(16bit)を0xXXXXで表記。
var onManufacturerData: ((String, Data, NSNumber, CBPeripheral, Data) -> Void)?
@Published var isScanning = false
@Published var scanningStatus = "停止中"
private var centralManager: CBCentralManager!
override init() {
super.init()
centralManager = CBCentralManager(delegate: self, queue: nil)
}
func startScan() {
guard centralManager.state == .poweredOn else {
print("ManufacturerDataScan: Bluetooth未準備 state=\(centralManager.state.rawValue)")
return
}
guard !isScanning else { return }
centralManager.scanForPeripherals(withServices: nil, options: [CBCentralManagerScanOptionAllowDuplicatesKey: true])
isScanning = true
scanningStatus = "スキャン中..."
}
func stopScan() {
guard isScanning else { return }
centralManager.stopScan()
isScanning = false
scanningStatus = "停止中"
}
}
extension ManufacturerDataScan: CBCentralManagerDelegate {
func centralManagerDidUpdateState(_ central: CBCentralManager) {
switch central.state {
case .poweredOn:
print("ManufacturerDataScan: Bluetooth On")
case .unauthorized:
print("ManufacturerDataScan: unauthorized")
case .unsupported:
print("ManufacturerDataScan: unsupported")
case .poweredOff:
print("ManufacturerDataScan: Bluetooth Off")
default:
break
}
}
func centralManager(_ central: CBCentralManager, didDiscover peripheral: CBPeripheral, advertisementData: [String: Any], rssi RSSI: NSNumber) {
guard let data = advertisementData[CBAdvertisementDataManufacturerDataKey] as? Data, !data.isEmpty else { return }
// Company IDは先頭2バイトLittle Endianで格納される
let companyId = data.prefix(2).reduce(0) { acc, byte in (acc << 8) | Int(byte) }
let key = String(format: "0x%04X", companyId)
let beacon_type = data[2]
let beacon_length = data[3]
if ( companyId == 0xFFFF ) {
if ( beacon_type == 0x02 && beacon_length == 0x10 ) {
let tempid = data.dropFirst(4)
onManufacturerData?(key, data, RSSI, peripheral, tempid)
}
}
}
}
COCOA で使っていた EN API 形式の受信機も iOS 版を作っていきます。つまりは、16 bit Service UUID を指定して受信するパターンです。CBCentralManager を使います。 これ、ずっと勘違いしていたのですが、iOS で 16 bit Service UUID は受信できますね。現在 EN API の 0xFD6F は塞がれたままなのですが、別の 16 bit Service UUID を送ると iOS で受信ができます。他の UUID とぶつからないように実験的に 0xFF00 を使うと受信できることが確認できます。
ちなみに iOS は 16 bit Service UUID で発信ができません。接触確認アプリの場合は受発信が必要なのでこのパターンは使えないのですが、何らかのデバイスで発信(m5stack など)したものを、iOS で受信することは十分可能です。なので、入場確認とかにこの方式が使えます。勿論、Bluetooth SIG で 16 bit Service UUID が必須になりますが…まあ、実験的にということで。
class BeaconScan(
private val context: Context
) {
companion object {
const val TAG = "BeaconScan"
private const val REQUEST_PERMISSIONS_CODE = 1001
// val SERVICE_UUID: UUID = App.SERVICE_UUID
val SERVICE_UUID: UUID = UUID.fromString("90FA7ABE-FAB6-485E-B700-1A17804CAA13") // FolkBears サービス
}
private val traceDeviceRepository = TraceDeviceRepository()
private var scanner: BluetoothLeScanner? = null
private var scanCallback : ScanCallback? = null
// Beacon スキャン結果を受け取るコールバック
var onReadTraceData: (TraceDataEntity) -> Unit = {}
var onIBeacon: (IBeaconAdvertisement) -> Unit = {}
private fun setupBeaconMonitoring() {
Log.d(TAG, "setupBeaconMonitoring")
if (!hasScanPermission()) {
Log.w(TAG, "BLE scan permission not granted; requesting")
requestScanPermission()
return
}
val bluetoothManager = context.getSystemService(Context.BLUETOOTH_SERVICE) as BluetoothManager
val adapter = bluetoothManager.adapter
scanner = adapter.bluetoothLeScanner
if (scanner == null) {
Log.e(TAG, "BluetoothLeScanner is not available")
return
}
val scanFilter = ScanFilter.Builder()
.setManufacturerData(0x004C, byteArrayOf(0x02, 0x15)) // Apple iBeacon の識別データ
// .setServiceUuid(ParcelUuid(SERVICE_UUID)) // フィルターが効かない
.build()
val scanSettings = ScanSettings.Builder()
.setScanMode(ScanSettings.SCAN_MODE_LOW_POWER)
.build()
scanCallback = object : ScanCallback() {
override fun onScanResult(callbackType: Int, result: ScanResult?) {
result?.let { scanResult ->
val parsed = parseIBeacon(scanResult) ?: return
val deviceAddress = scanResult.device?.address
val tempid = "%04x".format(parsed.major) + "%04x".format(parsed.minor)
val timestamp = parsed.timestamp
val dataEntity = TraceDataEntity(
tempId = tempid,
timestamp = timestamp,
rssi = parsed.rssi,
txPower = parsed.txPower
)
// traceDeviceRepository を使わない
onIBeacon(parsed)
/*
// 10秒以前を削除する
traceDeviceRepository.setTimestamp(timestamp = timestamp)
// デバイスアドレスが登録されていない場合のみ、データを読み込む
if (!traceDeviceRepository.checkMacAddress(deviceAddress ?: "")) {
traceDeviceRepository.readTempId(
mac = deviceAddress ?: "",
tempId = tempid,
timestamp = timestamp
)
onIBeacon(parsed)
// コールバックの呼び出し
onReadTraceData(dataEntity)
}
*/
}
}
override fun onScanFailed(errorCode: Int) {
Log.d(TAG, "onScanResult: error")
super.onScanFailed(errorCode)
}
}
Log.d(TAG, "iBeacon スキャン開始")
scanner?.startScan(listOf(scanFilter), scanSettings, scanCallback)
}
private fun hasScanPermission(): Boolean {
val scan = ContextCompat.checkSelfPermission(context, Manifest.permission.BLUETOOTH_SCAN) == PackageManager.PERMISSION_GRANTED
val legacy = ContextCompat.checkSelfPermission(context, Manifest.permission.BLUETOOTH) == PackageManager.PERMISSION_GRANTED
return scan || legacy
}
private fun requestScanPermission() {
val activity = context as? Activity ?: run {
Log.w(TAG, "Context is not Activity; cannot show permission dialog")
return
}
val needs = mutableListOf<String>()
if (ContextCompat.checkSelfPermission(context, Manifest.permission.BLUETOOTH_SCAN) != PackageManager.PERMISSION_GRANTED) {
needs += Manifest.permission.BLUETOOTH_SCAN
}
if (ContextCompat.checkSelfPermission(context, Manifest.permission.BLUETOOTH_CONNECT) != PackageManager.PERMISSION_GRANTED) {
needs += Manifest.permission.BLUETOOTH_CONNECT
}
// Fallback for pre-Android 12
if (ContextCompat.checkSelfPermission(context, Manifest.permission.BLUETOOTH) != PackageManager.PERMISSION_GRANTED) {
needs += Manifest.permission.BLUETOOTH
}
if (ContextCompat.checkSelfPermission(context, Manifest.permission.ACCESS_FINE_LOCATION) != PackageManager.PERMISSION_GRANTED) {
needs += Manifest.permission.ACCESS_FINE_LOCATION
}
if (needs.isEmpty()) return
ActivityCompat.requestPermissions(activity, needs.toTypedArray(), REQUEST_PERMISSIONS_CODE)
}
private fun parseIBeacon(result: ScanResult): IBeaconAdvertisement? {
val record = result.scanRecord ?: return null
val payload = record.getManufacturerSpecificData(0x004C) ?: return null
// iBeacon payload size should be 23 bytes: 0x02 0x15 + UUID(16) + major(2) + minor(2) + tx(1)
if (payload.size < 23) return null
if (payload[0] != 0x02.toByte() || payload[1] != 0x15.toByte()) return null
fun ByteArray.toHex(): String = joinToString(separator = "") { eachByte -> "%02X".format(eachByte) }
val uuidBytes = payload.sliceArray(2 until 18)
val serviceUuid = uuidBytes.toHex()
val major = (payload[18].toInt() and 0xFF) * 256 + (payload[19].toInt() and 0xFF)
val minor = (payload[20].toInt() and 0xFF) * 256 + (payload[21].toInt() and 0xFF)
val txPower = payload[22].toInt()
val rssi = result.rssi
return IBeaconAdvertisement(
serviceUuid = serviceUuid,
major = major,
minor = minor,
timestamp = System.currentTimeMillis(),
rssi = rssi,
txPower = txPower
)
}
///
/// @brief Beacon スキャンサービスを開始する
///
fun startScan() {
Log.d(TAG, "startScan")
setupBeaconMonitoring()
}
///
/// @brief Beacon スキャンサービスを停止する
///
fun stopScan() {
Log.d(TAG, "stopScan")
scanner?.stopScan(this.scanCallback)
scanner = null
}
}
EN API スキャン
同じパターンで EN API 型のスキャンコードを ENSimScan クラスとして作成します。EN API の 16 bit UUID 0xFD6F を使ってフィルタリングしてあります。実は、0xFD6F は EN API なので Android のほうでガードが掛かっている筈…なのですが、今は大丈夫そうですね。Android OS のバージョンによってはガードが掛かっている可能性があるので、別の 16 bit UUID に変えて実験するのが望ましいです。
class ENSimScan(
private val context: Context
) {
companion object {
const val TAG = "ENSimScan"
val SERVICE_UUID: UUID = UUID.fromString("0000FD6F-0000-1000-8000-00805F9B34FB")
}
private val traceDeviceRepository = TraceDeviceRepository()
private var scanner: BluetoothLeScanner? = null
private var scanCallback: ScanCallback? = null
// ENSim スキャン結果を受け取るコールバック
var onReadTraceData: (TraceDataEntity) -> Unit = {}
private fun setupScan() {
Log.d(TAG, "setupScan")
val bluetoothManager = context.getSystemService(Context.BLUETOOTH_SERVICE) as BluetoothManager
val adapter = bluetoothManager.adapter
scanner = adapter.bluetoothLeScanner
// 16 bit UUID
val serviceUuid = ParcelUuid(SERVICE_UUID)
val scanFilter = ScanFilter.Builder()
.setServiceUuid(serviceUuid)
.build()
val scanSettings = ScanSettings.Builder()
.setScanMode(ScanSettings.SCAN_MODE_LOW_POWER)
.build()
scanCallback = object : ScanCallback() {
override fun onScanResult(callbackType: Int, result: ScanResult?) {
fun ByteArray.toHex(): String = joinToString(separator = "") { eachByte -> "%02X".format(eachByte) }
result?.let {
val serviceData = it.scanRecord?.getServiceData(serviceUuid)
if (serviceData != null && serviceData.isNotEmpty()) {
val tempId = serviceData.toHex()
val deviceAddress = result.device?.address ?: ""
val timestamp = System.currentTimeMillis()
val rssi = result.rssi
val txPower = result.txPower
Log.d(TAG, "ENSim 検出: $deviceAddress tempId:$tempId rssi:$rssi tx:$txPower")
val dataEntity = TraceDataEntity(
tempId = tempId,
timestamp = timestamp,
rssi = rssi,
txPower = txPower
)
// traceDeviceRepository を使わない
onReadTraceData(dataEntity)
/*
traceDeviceRepository.setTimestamp(timestamp = timestamp)
// デバイスアドレスが未登録の場合のみ、新規として追加し、コールバックを通知
if (!traceDeviceRepository.checkMacAddress(deviceAddress)) {
traceDeviceRepository.readTempId(
mac = deviceAddress,
tempId = tempId,
timestamp = timestamp
)
onReadTraceData(dataEntity)
}
*/
}
}
}
override fun onScanFailed(errorCode: Int) {
Log.d(TAG, "onScanResult: error $errorCode")
super.onScanFailed(errorCode)
}
}
Log.d(TAG, "ENSim スキャン開始")
scanner?.startScan(listOf(scanFilter), scanSettings, scanCallback)
}
///
/// ENSim スキャンサービスを開始する
///
fun startScan() {
Log.d(TAG, "startScan")
setupScan()
}
///
/// ENSim スキャンサービスを停止する
///
fun stopScan() {
Log.d(TAG, "stopScan")
scanner?.stopScan(this.scanCallback)
scanner = null
}
}
GATT コネクションのスキャン
FolkBears のコネクション版では GATT で接続してから TempID を読み出す方式になっています。このとき、接続先のデバイスを見つけるためにスキャンをする必要があるのですが、これだけを試しています。実質的に iBeacon や EN API をスキャンをするときと同じになります。